Overview

3DiFACE is a novel diffusion-based method for synthesizing and editing holistic 3D facial animation from an audio sequence, wherein one can synthesize a diverse set of facial animations (top), seamlessly edit facial animations between two or multiple user-specified keyframes, and extrapolating motion from past motion (bottom).
Abstract
Video
Proposed Method
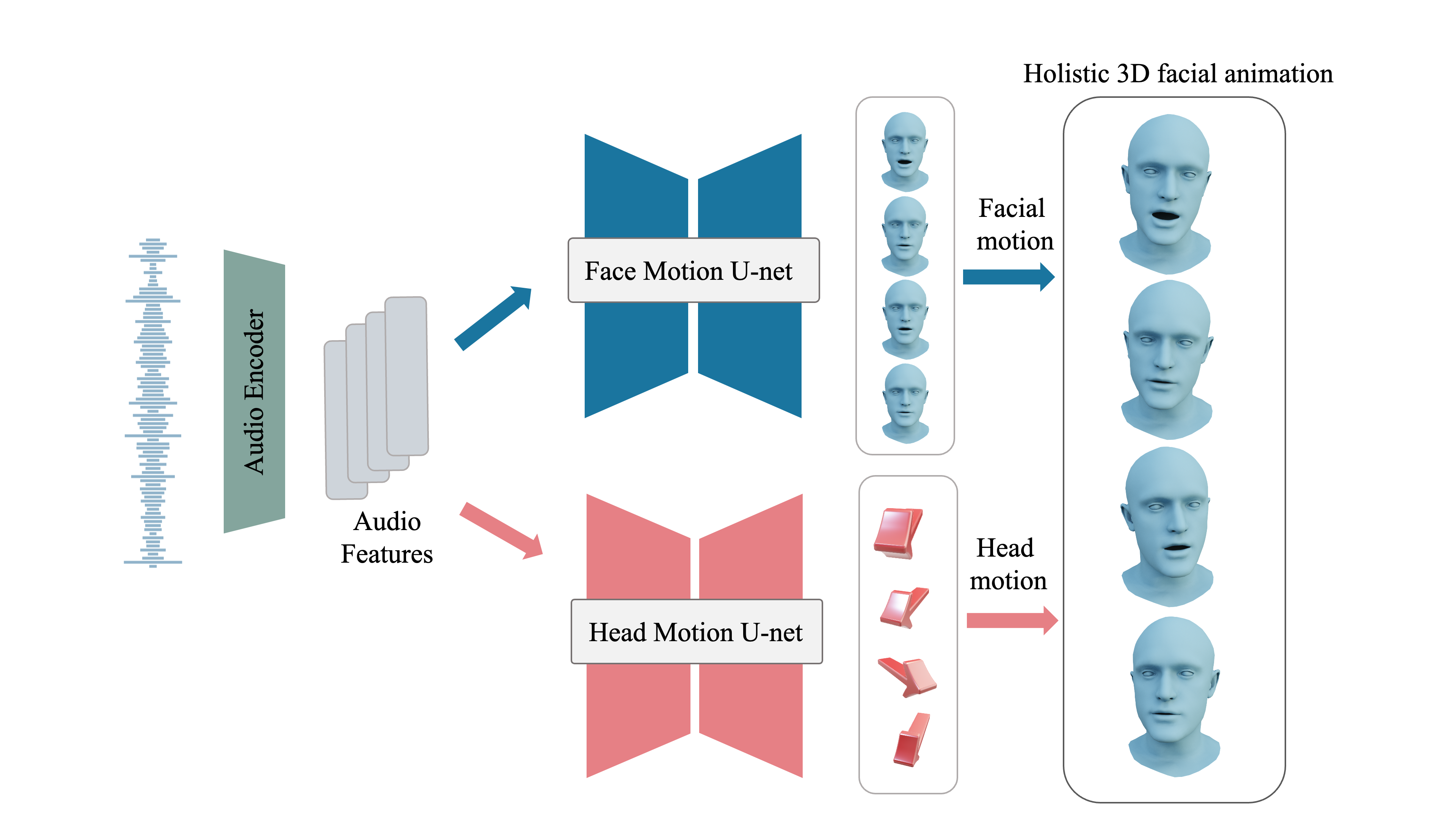
Our goal is to synthesize and edit holistic 3D facial animation given input audio signal. To acheive this, we model the facial and head motion using two diffusion-based networks, motivated by the fact that the face motion is highly correlated to the speech signal, while the head motion is relatively less correlated and thus requires a longer context of information, hence, a different training scheme (and data).
Editing
A user can control the synthesis process by either modifying an existing sequence or employing keyframes to direct the synthesis outcome.
Holisitc motion synthesis comparison
Lip motion synthesis comparison
Lip motion diversity comparison
Ablation: Editing
Ablation
BibTeX
@inproceedings{
thambiraja2025diface,
title={3Di{FACE}: Synthesizing and Editing Holistic 3D Facial Animation},
author={Balamurugan Thambiraja and Malte Prinzler and Sadegh Aliakbarian and Darren Cosker and Justus Thies},
booktitle={International Conference on 3D Vision 2025},
year={2025},
url={https://openreview.net/forum?id=8qpjYG1x8I}
}