Overview
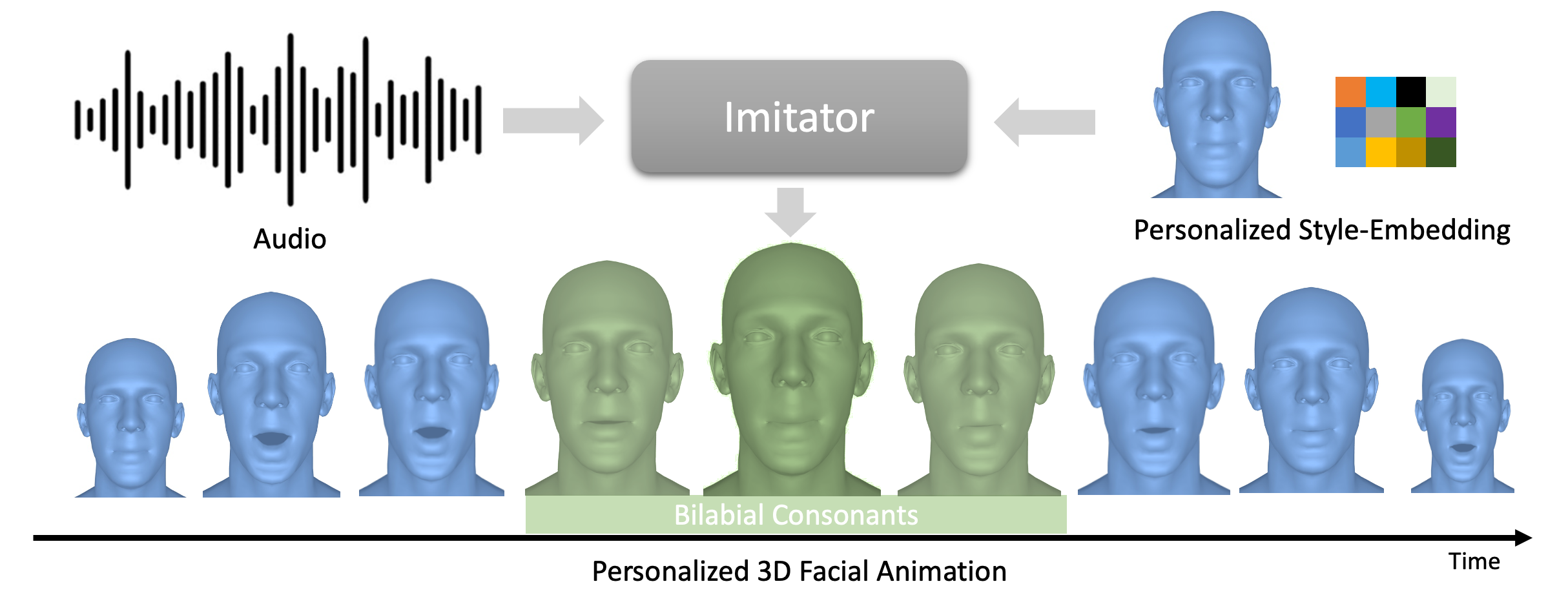
Imitator is a novel method for personalized speech-driven 3D facial animation. Given an audio sequence and a personalized style-embedding as input, we generate person-specific motion sequences with accurate lip closures for bilabial consonants ('m','b','p'). The style-embedding of a subject can be computed by a short reference video (e.g., 5s).
Abstract
Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements.
To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically,
To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions.
Through detailed experiments and user studies, we show that our approach improves Lip-Sync by 49% and produces expressive facial animations from input audio while preserving the actor’s speaking style.
Video
Proposed Method
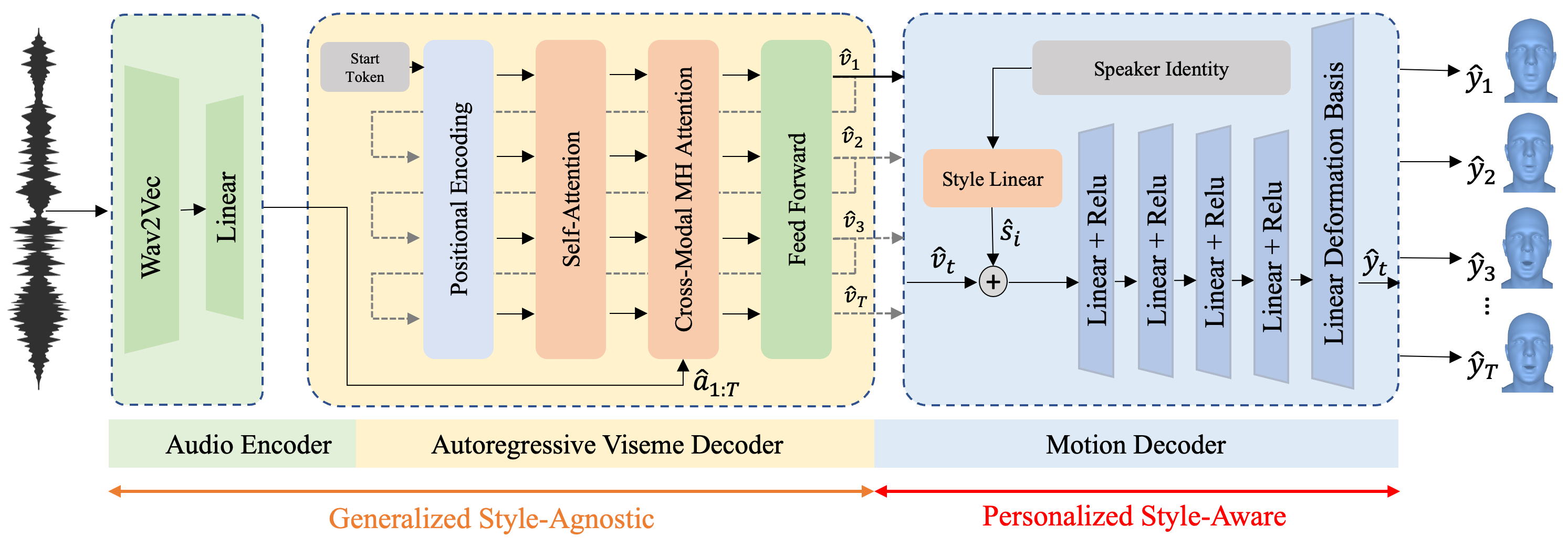
Overview of the proposed method. Our method takes audio as input and encodes it to audio embedding using a pre-trained Wav2Vec2.0 model . This audio embedding â1:T is interpreted by an auto-regressive viseme decoder which generates a generalized motion feature v̂1:T. A style-adaptable motion decoder maps these motion features to person-specific facial expressions ŷ1:T in terms of vertex displacements on top of a template mesh.
Result
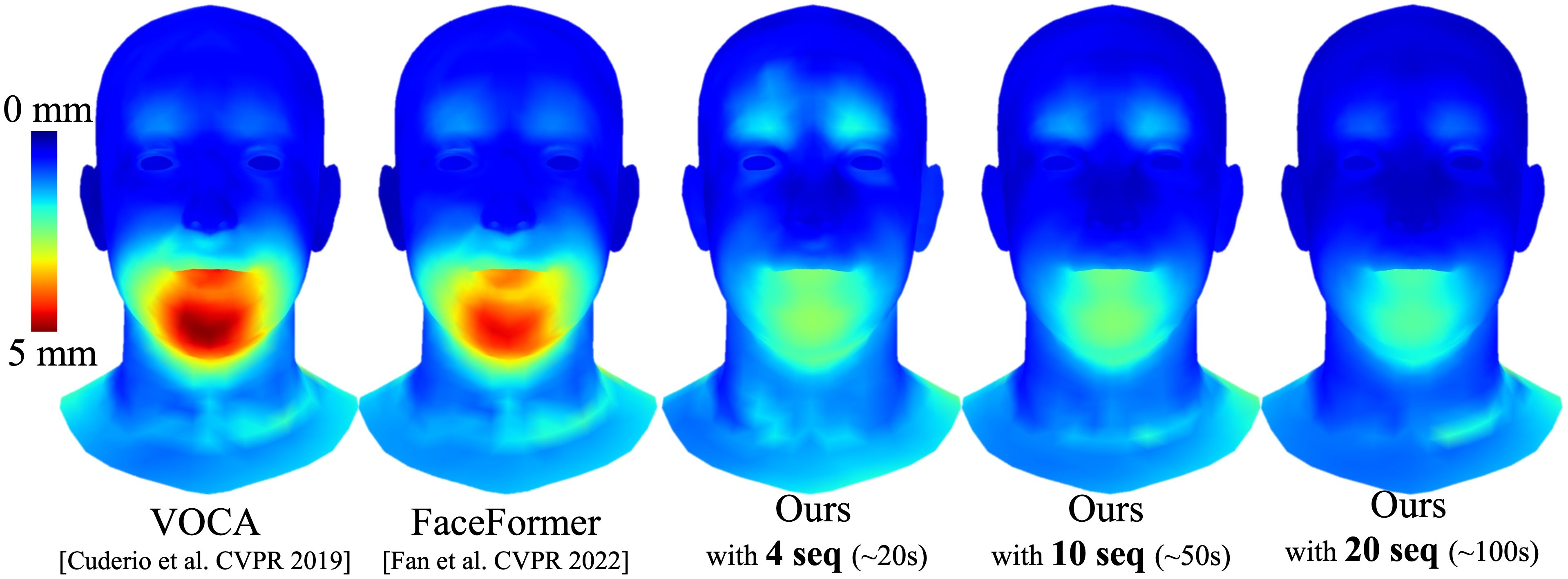
Comparison of the different methods on the VOCA test set with mean L2 vertex distance error.
Impact of Personalization
Impact of Lip Contact Loss
Cross-Style and Audio generalization
BibTeX
@InProceedings{Thambiraja_2023_ICCV,
author = {Thambiraja, Balamurugan and Habibie, Ikhsanul and Aliakbarian, Sadegh and Cosker, Darren and Theobalt, Christian and Thies, Justus},
title = {Imitator: Personalized Speech-driven 3D Facial Animation},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {20621-20631}
}